Motivation
The code below was originally written by Ian McDonald. If you’re interested in learning more about the data, this page has an excellent overview.
Read Data
readr makes reading rectangular data a breeze. Below we read data concerning members of congress.
library(readr)
metadata <- read_csv(
"col_name , col_width
congress , 4
icpsr , 6
st_code , 3
cd , 2
st_name , 8
party_code , 5
mc_name , 15
dim_1 , 10
dim_2 , 10
dim_1_se , 10
dim_2_se , 10
dim_1_2_corr , 8
log_lik , 11
num_votes , 5
num_class_err , 5
geo_mean_prob , 10"
)
members <- read_fwf(
"ftp://k7moa.com/junkord/HL01113D21_BSSE.DAT",
fwf_widths(widths = metadata$col_width, col_names = metadata$col_name)
)Transform Data
dplyr makes manipulating data a pleasure.
library(dplyr)
representatives <- members %>%
filter(
congress >= 88,
!(cd %in% c(0, 98, 99)),
party_code == 100 | party_code == 200
) %>%
mutate(year1 = congress * 2 + 1787) %>%
arrange(desc(year1))
democrats <- representatives %>% filter(party_code == 100)
republicans <- representatives %>% filter(party_code == 200)Visualize Data
ggplot2 makes visualizing data a joy.
library(ggjoy)
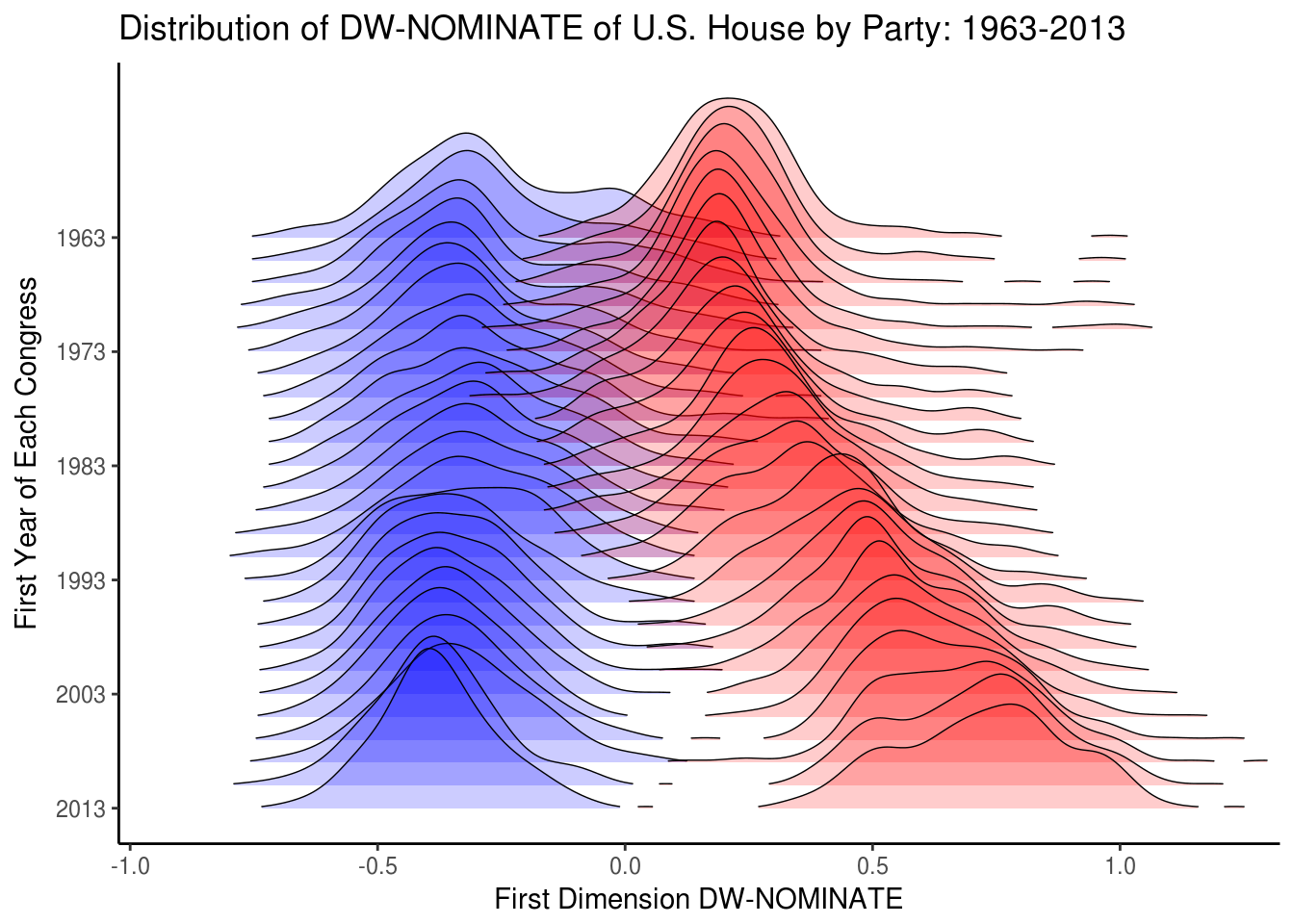
ggplot(representatives, aes(x = dim_1, y = year1, group = year1)) +
geom_joy(data = democrats, fill = "blue", scale = 7, size = 0.25, rel_min_height = 0.01, alpha = 0.2) +
geom_joy(data = republicans, fill = "red", scale = 7, size = 0.25, rel_min_height = 0.01, alpha = 0.2) +
theme_classic() +
scale_x_continuous(limits = c(-1, 1.3), expand = c(0.01, 0), breaks = seq(-1, 1, 0.5)) +
scale_y_reverse(breaks = seq(2013, 1963, -10)) +
ggtitle("Distribution of DW-NOMINATE of U.S. House by Party: 1963-2013") +
ylab("First Year of Each Congress") +
xlab("First Dimension DW-NOMINATE")